
咨询QQ:2083503238、1684129674、480934277(请勿重复咨询) 咨询微信:qiangfans
jmeter学习指南之参数化CSV Data Set Config
- 2018-12-28 20:14:00
- 小静
- 原创 1326 投稿得红包
点击链接加入QQ群 522720170(免费公开课、视频应有尽有):https://jq.qq.com/?_wv=1027&k=5C08ATe
今天大家一起来学习一下参数化的一个重要工具,我们在写脚本时,经常要用到参数化,而实现参数化最常用的方法之一就是使用CSV Data Set Config元件,使用方便,功能强大。
简单的使用方法估计大家都会,或者说很容易就会了,但是,如果说是比较复杂的配置,估计就有很多人会被绕晕了(我刚开始也经常晕~),今天咱们就详细看看,怎么才能不晕!哈哈
首先来看一眼长啥样,相信大家都比较熟悉

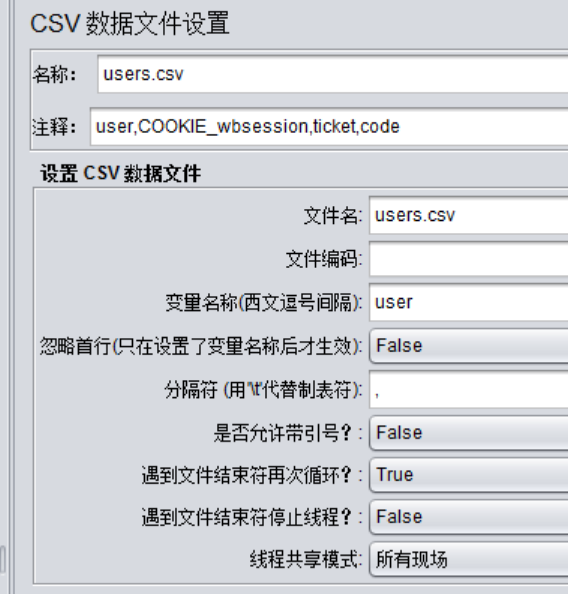
该元件的作用:
从文件中读取变量值,用于变量的参数化,可设置多种读取方式。
各填写项说明:
1、名称、注释:元件的名称及注释,可自定义
2、Config the CSV Data Source:配置数据源
1)Filename:csv文件的名称
注意:这里要包括文件的路径,在4.0版本中可以点击右侧的浏览按钮选择文件,会自动带上文件的绝对路径;
另外,当csv文件在jmeter的bin目录或脚本目录时,只需给出文件名即可;
使用相对路径时,jmeter默认先去bin目录下查找,然后去脚本目录下查找;
2)File encoding:csv文件编码
默认使用当前操作系统的编码格式;
如果文件中包含中文乱码时,可尝试utf-8、gbk等;
3)Variable Names(comma-delimited):
csv文件中各列的名字(有多列时,用英文逗号隔开列名);
名字顺序要与内容对应,这个变量名称是在其他处被引用的,所以为必填项。
4)Delimiter(use “t” for tab):csv文件中的分隔符(用”t”代替tab键)
一般情况下,分隔符为英文逗号,保持默认就行
5)Allow quoted data?:是否允许数据内容加引号
6)Recycle on EOF?:
到了文件尾是否循环,True—继续从文件第一行开始读取,False—不再循环;
此项与下一项的设置为互斥关系,即true-false,或false-true;
7)Stop thread on EOF?:
到了文件尾是否停止线程,True—停止,False—不停止;
注意:当Recycle on EOF设置为True时,此项设置无效。
8)Sharing mode:共享模式
All threads –所有线程,此元件作用范围内的所有线程共享csv数据,每个线程依次读取csv数据,互不重复;
Current thread group—当前线程组,在此元件作用范围内,以线程组为单位,每个线程组内的线程共享csv数据,依次读取数据,互不重复;
Current thread—当前线程,在此元件作用范围内,每次循环中所有线程取值一样;
下面重点分析一下Allow quoted data和Sharing mode:
1、Allow quoted data?:是否允许带双引号的数据
此项实际是控制csv文件中的双引号是否为有效字符;
如果数据带有双引号且此项设置TRUE,则会自动去掉数据中的引号使能够正常读取数据,且即使引号之间的内容包含有分隔符时,仍作为一个整体而不进行分隔;
如果数据带有引号且此项设置为FALSE,则读取数据报错;
如果希望双引号字段中间再包含双引号,则需要加两个双引号来代表单个双引号。(啊啊啊,太拗口了!!!)
如下图所示,此项设置为true时,"2,3"-->2,3;"4""5"-->4"5

2、Sharing mode:共享模式
(1)All threads:针对所有线程组的所有线程,每个线程取值不一样,依次取csv文件中的下一行。
假如说有线程1到线程n (n>1),线程1取了一次值后,线程2取值时,取到的是csv文件中的下一行,即与线程1取的不是同一行。不管是单个线程组还是多个线程组,每个线程都是依次取下一行。需要注意的是,当一个线程组中有多个请求时,对于每个线程来说,在一次循环中每个请求的取值是一样的。
下面举例说明:
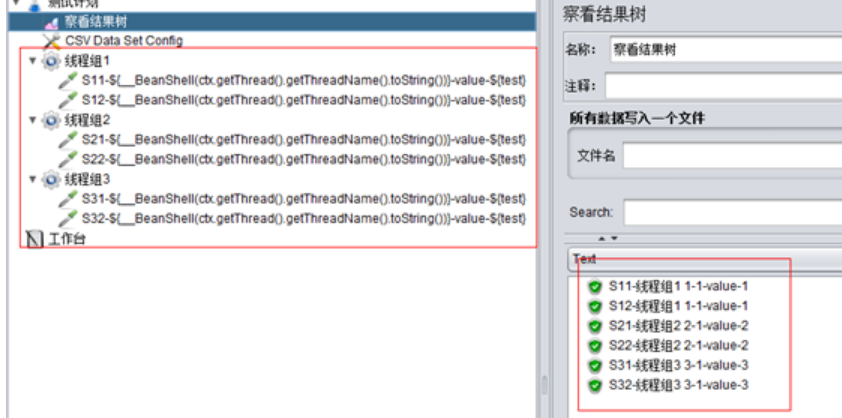
A、设置线程组1、2、3分别为1并发、1次循环,且各线程组按顺序执行:
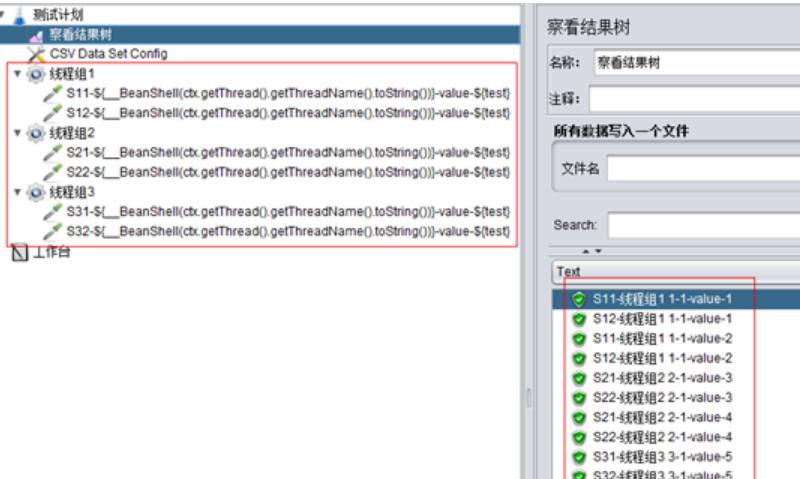
B、设置线程组1、2、3分别为1并发、2次循环,且各线程组按顺序执行:
C、设置线程组1、2、3分别为2并发、1次循环,且各线程组按顺序执行:
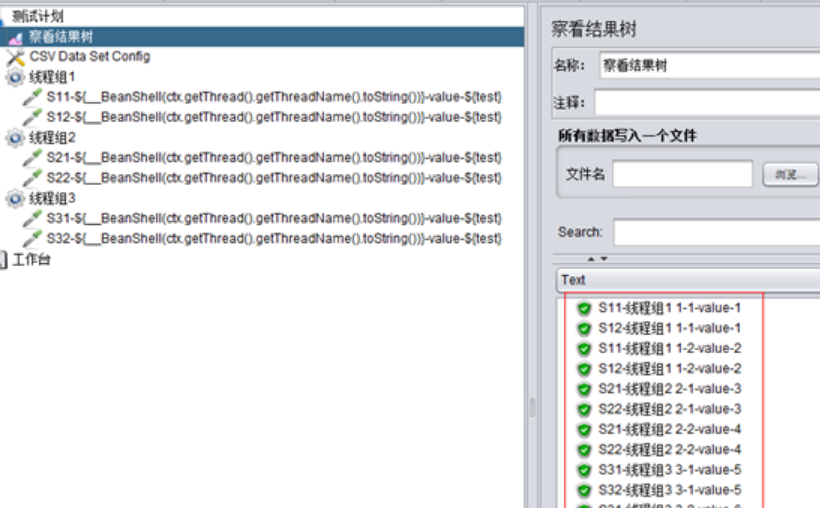
大家可以仔细比较一下上图和上上图的区别,乍一看貌似是一样的,但是实际却是不同的线程,怎么区分不同线程呢?
可以使用一个函数来判断:
${__BeanShell(ctx.getThread().getThreadName().toString())}
这个函数可以输出类似这样的内容:“线程组1 1-2“,前面是当前线程组的名称-线程组1,后面是线程组id,然后是线程id,现在再比较上面两图中,发现是线程id不一样。
总体来说就是,在All Threads模式下,并发数和循环数都会读取不同的csv数据,但是同一线程组内的多个sampler总是取相同的值。
(2)Current thread group:当前线程组,
取值情况是:以线程组为单位,每个线程组内的线程都会从第1行开始取值并依次往下进行取值。
举例如下:
A、设置线程组1、2均为2并发、1循环:
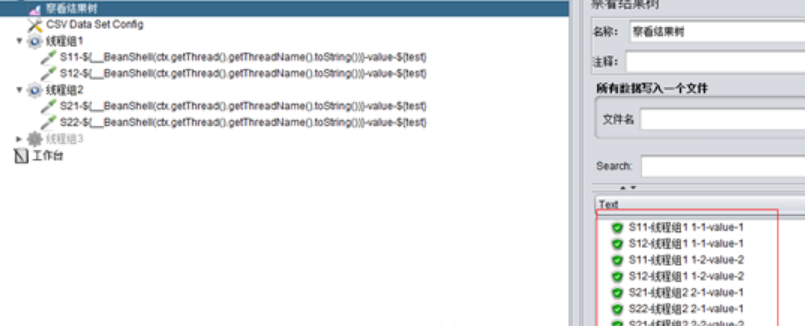
(3)Current thread:当前线程。
取值情况是:每个线程都会从第1行开始取值并依次往下进行取值,在同一次循环中所有的线程取值一样。
举例如下:
A、设置线程组1、2均为2并发、1循环:

上面两个图看起来好像是一样的呀?再仔细看一下,后面的test参数取值是不同的。
为什么不同呢?本来想认真的解释一番,但是组织了很久的语言,还是感觉没说清楚。
这一块的逻辑是“只可意会,不可言传”,必须要靠自己亲自实验,慢慢体会才行。
最后,给大家一个小作业:
如何通过设置Sharing moder的方法来实现多个sampler中的参数可以依次不重复的取同一个csv文件中的值?
jmeter视频:https://edu.51cto.com/course/14305.html


